Experience the perfect balance of performance and price with the new Mimosa C6x Lite Edition — built for today, ready for tomorrow.

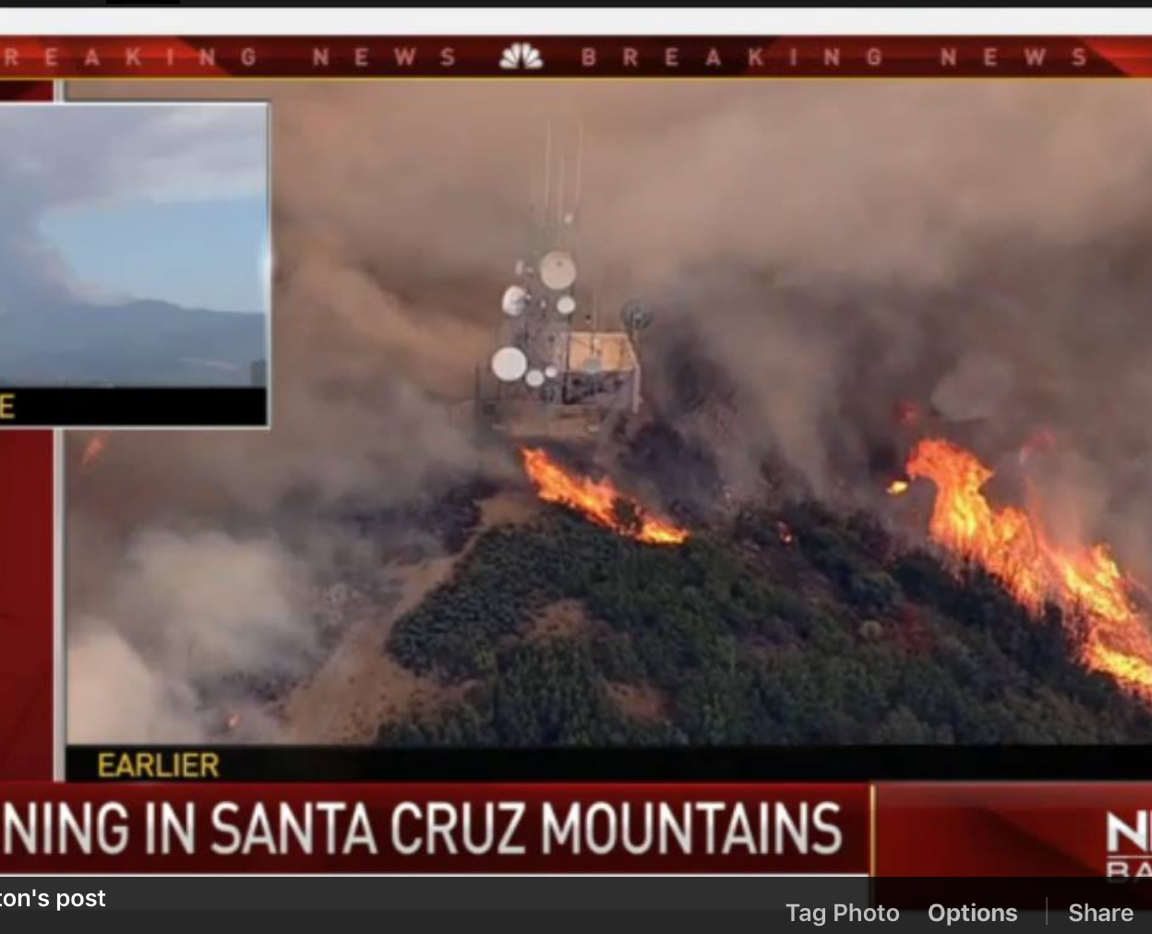
Many of you may have read about the Loma fire that started in California’s Santa Cruz mountains on September 26, 2016, destroying many buildings and threatening several tower locations. Two of the tower sites, heavily used as a primary route for telecommunications and Internet traffic, were surrounded by flames that damaged generators, melted AC lines, and engulfed radios mounted less than 6m (20 feet) AGL. Mimosa uses these sites as a primary route for providing Internet service to both our headquarters building, and to several test sites with live users on both sides of the mountains. In light of this fire, we thought it would be a good time to discuss how to plan and maximize network availability during disasters.
In the field of computer networking, there are a number of standard techniques for achieving five nines (99.999%) availability, which translates to approximately 5 ½ minutes per year of downtime maximum – what many users have come to expect.
Some of these techniques include power redundancy, hardware redundancy, failover architecture to support them, smart routing, geographic and path diversity, remote access, and active monitoring. These techniques can and should be extended to RF links such that they approach the availability of their wired counterparts. This article will outline each of these techniques and describe how to apply them for robust RF network design.

Power outages are one of the primary failure modes in RF networks. Antennas tend to be installed in remote locations with a single power source. Even when a generator is available to export power after a grid-outage, there is often transfer switching delay in generator startup that causes radios to reboot.
One solution for this problem is the introduction of an uninterruptable power supply (UPS). Aside from protecting against power surges and dips, a UPS can provide power during the time between the grid outage and generator startup. In locations without a generator, the UPS should be sized such that the holdup time exceeds the longest expected grid power outage.
Photovoltaic (PV) power systems are another option. In addition to PV panels, a complete PV system should also contain a charge controller, a bank of batteries, and an inverter. Inverters are available in grid-tie (solar as backup), or off-grid (solar only) configurations.
In both solutions above, matching the expected loads with the output from the backup power solution is critical. This entails summing the power required for all loads and ensuring that the source of backup power is equal or greater, and that it can sustain the loads over a set period of time.
It is important to identify single points of failure that could cause a network outage and then identify a workaround for each. In most cases, the workaround involves having more than one device (e.g. radio, switch, router, etc.) in parallel that serves the same function, either used at the same time (aggregated) to increase capacity, or separately as a failover option.
Installing a second parallel RF link operating on another frequency provides even better downtime insurance. While this could be achieved at the same location (e.g. two Mimosa B5 radios using four independent 20 MHz channels), geographic diversity would also protect against site-specific problems such as a power outage at a single point.
For maximum network-level availability, Mimosa recommends using both redundancy and geographic diversity to avoid single points of failure.

The entire network must be configured to failover, or self-heal, in a way that doesn’t cause a service outage for downstream users.
While it is beyond the scope of this article to describe every method for achieving the goal of fault tolerance, there are two network routing protocols that provide an excellent starting point: BGP and OSPF. These protocols were designed to enable external and internal network redundancy, respectively.
In a scenario where you have two upstream Internet providers and an edge router installed at each facility in a colocation cabinet, each router can be configured to use the Border Gateway Protocol (BGP), which advertises reachability information about your network’s IP space to the outside world. The two routers are called neighbors (or peers), meaning that they share the responsibility for advertising your network to the Internet. Another term for this relationship is “multi-homing”. If one path to a router becomes impaired, then the other router fully takes over advertising the IP space through another path. Once multiple routes to your network are available from the public Internet to your IP space, it is time to focus on internal redundancy.
The Open Shortest Path First (OSPF) protocol allows routers within your network to communicate and dynamically adjust topology in the case of link failures. The implication is that static routing is no longer necessary since OSPF learns the shortest path from one IP to another at each router. In OPSF-routed networks, one router is nominated as the designated router (DR) that publishes topology information to other routers in order to minimize traffic related to discovering routes. If the designated router (DR) becomes impaired, a backup DR (BDR) takes over. Path costs can be applied to specific interfaces (individual Ethernet ports) to control how OSPF routes traffic over multiple links to the same destination.

Occasionally, there are times when testing or troubleshooting are most easily performed while connected to the same subnet as the devices which need attention. If your transit links are IP addressed within a small subnet, consider interconnecting an inexpensive linux server and your radios to the same switch so that you can SSH into the linux server and access the entire subnet from a particular network node. This is especially useful in a network containing parallel links where the server is configured with two network cards, one on each subnet.
The advantages are that updates and tests can be performed locally without configuring every device for remote access over the Internet (a potential security risk), or without consuming extra bandwidth to administer each device in the case of firmware upgrades.
As a full-featured operating system, linux comes standard with a robust security model, built-in tools for troubleshooting network issues (e.g. ping, traceroute, netstat, arp, dig), tools for accessing other devices (telnet, SSH), and it can even function as a firewall or router (iptables).
For advanced troubleshooting, third-party open-source tools like Iperf can be installed to perform network throughput tests by traffic type (TCP, UDP), and with varying packet and window sizes.

To prevent downtime and costly truck rolls, consider installing IP-controlled remote power switches (such as the ones available from Digital Loggers, Inc.) to cycle power if one of your devices hangs or requires a hard reset. These devices are similar to regular power strips, but provide the ability to cycle power to specific devices through their built-in Ethernet interface. They are typically placed inline between the power supply and other devices being served, such as routers, switches and POE’s. A request to cycle power simply disconnects, and then reconnects the power output to the device requiring a reboot.
If you happen to have parallel links that terminate at the same location, install two IP power strips and cross-connect their Ethernet interface. That is, connect the power to one link and the Ethernet port to the other link. This way if one of the two parallel links goes down, you will still be able to remotely power cycle devices through the Ethernet port connected to the active link.
Some commercially available switches provide PoE power to your radios provided that they have compatible voltage, the same power standard (802.3at/af or passive), and an adequate power budget. Cycling PoE power to a particular port through the switch GUI control accomplishes the same thing as cycling AC power to a standalone PoE.
There’s nothing more satisfying (or anxiety-reducing), than seeing a sea of green devices on a network map, but when one of your devices needs attention, you’d rather know about it as soon as possible to avoid downtime.
Mimosa Networks’ free cloud-based network management tool (“Manage”) provides a detailed view of device performance over time that can help find ways to strengthen your network. Using the topology diagram, you can learn to identify single points of failure and determine which parent device may be affecting the accessibility of downstream child devices.
Several commercial monitoring systems are available (e.g. Solarwinds, Zenoss) that arm the operator with the ability to define devices and their placement within a network topology. Their open-source counterparts sometimes require a more detailed understanding about how the monitoring system operates, and knowledge of what data and the methods for collecting it are available from the monitored device. Other free or open-source options include Nagios, OpenNMS and Zabbix.

What was the outcome in the Loma fire? Though the tower sites had both UPS and generators, the generators were located outdoors and did not start because their controls were damaged before the AC power was lost. In this situation, dynamic routing protocols and geographic diversity were the only possibility for recovery. With good planning, traffic was automatically diverted to secondary routes with the next lowest cost, and connectivity continued for the majority of end points.
As you can see, achieving five nines network reliability requires a combination of different techniques that should also be applied across RF microwave links as well as other interconnected network equipment. A diligent effort, starting with design and extending through deployment and monitoring, is necessary to avoid single points of failure and to ensure that your customers experience high availability for their critical applications.
Experience the perfect balance of performance and price with the new Mimosa C6x Lite Edition — built for today, ready for tomorrow.